


Many enterprises invest in AI platforms with the right intent but still struggle to operationalize models at scale. The challenge is rarely the model itself. More often, the real issue lies in everything around it – inconsistent environments, manual data preparation, fragmented tooling, weak release discipline, and limited governance once models move closer to production.
In one recent Dataiku implementation, this played out clearly. Forecasting workflows were split across the platform, local Python notebooks, and Excel-based preparation steps – three different surfaces, each with its own version of the truth. The real opportunity wasn’t simply to deploy models faster. It was to put in place the MLOps operating model required to run them reliably, govern them effectively, and improve them continuously over time. That work reinforced six practical learnings for any enterprise building MLOps capabilities in Dataiku.
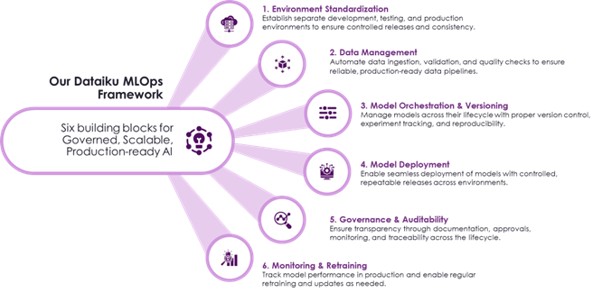
The Six MLOps Lessons from Dataiku Implementation
1. Standardize Environments Early
Environment design should never be treated as a late cleanup task. When the same setup is used for experimentation, testing, and operational execution, releases become harder to control and failures become harder to isolate – often because no one can say for certain which version of the environment actually broke.
Separating development, QA, and production early creates a cleaner path for promotion, reduces release risk, and gives teams a much stronger base to scale on. It’s a small upfront decision that prevents a much larger downstream cost.
2. Treat Data Readiness as Part of MLOps
Reliable model execution starts with reliable data intake. In this implementation, manual file exports, formatting fixes, and field alignment created avoidable delays and quality risk – the kind of friction that’s easy to dismiss as a one-time fix, until it happens every release cycle.
Bringing ingestion, validation, profiling, and data quality checks directly into Dataiku turned data readiness into a managed production capability, rather than an informal pre-step that lived outside the system and outside anyone’s visibility.
3. Unify Model Lifecycle Management Across Tools
Most enterprises have a mixed model estate. Some models are built in Dataiku, while others remain in notebooks or custom Python workflows, often shaped by whoever happened to build them first. Without a common model lifecycle, operations become fragmented and too dependent on individual delivery styles rather than a shared standard.
Bringing both Dataiku-native and external Python models into one structured framework made training, inference, promotion, and retraining more repeatable – and far easier to govern, regardless of where a model originated.
4. Make Deployment a Controlled Release Process
A model running in production is not the same as having a production-ready deployment process. Informal handoffs, manual transfers, and environment-specific workarounds can get a model live once, but they create uncertainty every time after that – uncertainty that tends to surface at the worst possible moment.
A stronger approach treats deployment as a release discipline: environment consistency, dependency control, validation checkpoints, and a clear, repeatable path from QA to production.
5. Embed Governance into Delivery
Governance works best when it is built into the workflow rather than added after the fact. Approval steps, documentation, version traceability, and release criteria should sit directly in the path to production – not bolted on right before launch as a compliance formality.
In practice, this improves transparency, strengthens accountability, and makes model governance an enabler of scale rather than a separate control layer that shows up too late to actually help.
6. Design for Monitoring and Retraining from Day One
Deployment is the start of a model’s lifecycle, not the end of it. Data patterns shift. Business conditions change. Models need structured monitoring, evaluation, and refresh processes to stay reliable as the world around them moves.
By planning for performance tracking, scheduled evaluation, and champion-challenger management from the start, organizations build an operating model that supports continuous improvement – not just a one-time deployment success that quietly decays.
Benefits of the Approach
Although this work focused on forecasting, the lessons extend well beyond one use case. A strong MLOps foundation creates reusable value across enterprise AI programs:
- Reduced dependency on manual processes
- Clearer separation between development and production
- More reliable and repeatable model execution
- Stronger governance and auditability
- Better support for monitoring, retraining, and model evolution
- A scalable backbone for future AI and GenAI initiatives
Final Thought
The value of MLOps was never about making a model run once. It’s about creating the conditions for that model to run consistently – with the right data, in the right environment, through the right controls, and with enough visibility to keep improving over time.
That’s what turns AI from experimentation into enterprise capability.
Looking to Scale Your Dataiku MLOps Capabilities?
Partner with Infocepts to design a scalable MLOps operating model that accelerates model deployment, strengthens AI governance, and delivers reliable, production-ready AI across the enterprise.
Ready to scale your AI models from experimentation to enterprise-grade execution?
Build a robust MLOps foundation to deliver consistent, governed, and production-ready AI at scale


