


The Agentic Enterprise Is No Longer a Vision — It’s Being Built Now
Prologue: A Declaration, Not a Roadmap
Every technology summit has a heartbeat — a thesis that runs through every keynote, every session, every conversation in the hallway. At Snowflake Summit 2026, that thesis was impossible to miss:
The enterprise AI race is not being won by the company with the best model. It is being won by the company that gives its models the best data, the richest context, and the tightest governance.
I have been working at the intersection of data platforms and enterprise AI for a while now, and this Summit felt different. Not because of any single announcement, but because the gap between what is architecturally possible and what enterprises are actually deploying is visibly narrowing. The conversations I had on the floor reflected that. People were not talking about AI in the abstract anymore — they were talking about agent deployments that went wrong, governance frameworks that held up under pressure, and context problems that turned out to be harder than the model selection.
Snowflake’s platform keynote was structured as four acts — a deliberate framing that mapped the evolution of the platform onto the evolution of the industry. What follows is my read of each act, layered with observations from the sessions I attended, and what I believe it means for enterprises trying to turn AI investment into real business outcomes.
The Four Acts at a Glance
If you want the simple version before the detail, this is the map I took away from the keynote.
- Act I — The Erasure of Friction: Building, migrating, and deploying intelligent applications is getting dramatically easier.
- Act II — The Bastion of Trust: Governance is becoming the operating layer that makes enterprise AI usable at scale.
- Act III — The Liberation of Data: Open interoperability is emerging as the architecture bet that will matter most.
- Act IV — The Omnipresence of Intelligence: Intelligence is moving out of specialist teams and into everyday workflows.
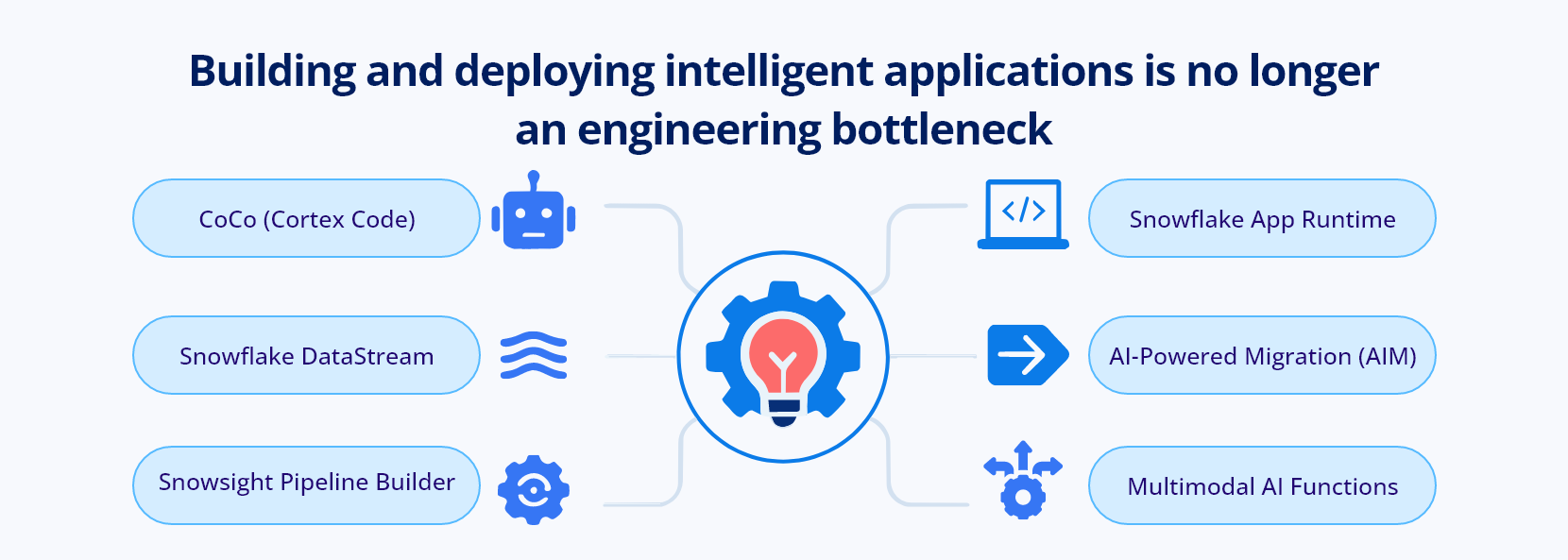
Act I — The Erasure of Friction
Building and deploying intelligent applications is no longer an engineering bottleneck.
What Stood Out
Christian Kleinerman (EVP Product) opened with a line borrowed from Arthur C. Clarke: “Any sufficiently advanced technology is indistinguishable from magic.” The subtext was clear — what feels like magic today should feel like infrastructure by next year.
The announcements in this act were all aimed at compressing the distance between idea and production:
- CoCo (Cortex Code) is now in GA on desktop, having grown from zero to 7,100+ organizations in roughly five months. The ML lifecycle — from data prep to model deployment — is being automated end to end.
- Snowflake DataStream was announced: a fully managed, Kafka-compatible streaming ingestion layer, native to Snowflake. Real-time data pipelines no longer require a separate infrastructure stack.
- Snowsight Pipeline Builder lets teams visually construct data pipelines without writing infrastructure code.
- Snowflake App Runtime now supports deploying Node and Python applications natively inside Snowflake — compute moves to the data, not the other way around.
- AI-Powered Migration (AIM) automates the translation of code and schema from legacy systems to Snowflake.
- Multimodal AI Functions extend native processing to unstructured data alongside structured.
Why It Matters
I want to be direct about something here, because I think it is often softened in conversations with clients: the engineering effort required to build and deploy data and AI solutions is commoditizing at speed. CoCo and AIM are not incremental quality-of-life improvements. They represent a structural shift in where human expertise creates value.
I sat in multiple sessions across this Summit and the pattern was consistent — organizations that had spent years and significant budget building custom migration accelerators, pipeline frameworks, and ingestion layers were quietly reassessing. Not because the work was bad, but because the platform now does a version of it natively, and the maintenance overhead of keeping custom tooling aligned with a fast-moving platform is a tax that compounds.
The organizations that will pull ahead are the ones that recognize this shift early and redirect engineering effort toward the problems the platform cannot solve: domain-specific data quality, proprietary business context, and the institutional knowledge that makes data meaningful. The platform is doing the plumbing. The question every data leader should be asking their team right now is — what are we doing with the pipes?
There is also a cost conversation worth having clearly. New managed services carry a per-use price. But the TCO calculation, when you fold in infrastructure, engineering time, and operational overhead, almost always favors the platform service. The conversation with business stakeholders needs to move from “what does this cost?” to “what does it cost us to not use it and maintain the alternative ourselves?”
What I’d Do Next
- Anything built to accelerate migration from legacy systems needs to be repositioned to complement AIM and CoCo like native offerings, not replicate them. The value we add is domain intelligence layered on top, not the infrastructure layer itself.
- The speed of CoCo means engineering teams will build things fast — sometimes too fast. Enterprises need a governed experimentation model: enough freedom to move quickly, enough structure to decide confidently what is worth productionizing.
- Before any AI conversation starts, the first question should be “what data and context are we giving it?” — not “which model should we use?” That reframe consistently changes the scope and success rate of the work.
Act II — The Bastion of Trust
Governance is not a brake — it is how you build AI that people actually rely on.
What Stood Out
This was the act I was most watching closely going in, and it landed well. The quote that cut through the noise:
“Governance is not for holding back — it is an enabler of speed, confidence, and assurance.”
I have said versions of this to clients for years. Hearing it from the main stage, backed by platform capabilities that make it architecturally real, matters. Governance is moving from a policy conversation to an infrastructure conversation — and that is a meaningful shift.
Key announcements:
- Horizon AI Guardrails — prompt injection protection and sensitive data protection guardrails, now in GA. These are runtime enforcement mechanisms, not policies that live in a document somewhere. They intercept unsafe agent behaviors before they cause harm.
- Data Exfiltration Protection — prevents data from being downloaded or surfaced, even within Snowsight. I see this as the foundation of data security for an agentic world, not just a compliance checkbox.
- Horizon Context — structured around three verbs: Collect, Enrich, and Activate. This is Snowflake’s answer to the enterprise context problem — how do you make the institutional knowledge of a business reliably available to AI agents?
- AI-Driven Governance Application — currently in private preview, this applies AI to governance itself: automated classification, tagging, and posture reporting at scale.
- Attribute-Based Access Control (ABAC) for users and agents — governance policies that travel with the data, not just the role.
A session on governance best practices introduced a three-part taxonomy that I found genuinely useful for structuring conversations with enterprise teams:
- Governance for Data — classifying, tagging, and protecting data assets; the foundation most enterprises are working in today.
- Governance with AI — using AI to automate governance work: CoCo-driven classification profiles, automated tagging, posture reporting.
- Governance for AI — masking policies, guardrails, and audit trails designed specifically for agent workloads and model interactions.
Most enterprises are operating primarily at layer one. The urgency is getting to layer three before the agents are already running.
Why It Matters
Enterprise Context was the most consistent underlying theme across every part of this Summit — not a product, but a condition. Here is the practical reality: most enterprises have accumulated decades of institutional knowledge. It lives in documentation, in the memory of long-tenured employees, in business rules written for systems that have since been replaced, in data dictionaries that are partially complete and infrequently updated. That knowledge is exactly why those organizations have grown and continue to compete. But it is scattered, inconsistent, and functionally invisible to AI agents.
Horizon Context is Snowflake’s framework for addressing this. But the framework is only as good as the organization’s discipline in feeding it. The enterprises that build a systematic context lifecycle — capturing business definitions, enriching them over time, and activating them reliably for agent use — will accumulate an AI advantage that no model upgrade from any vendor can erase. That is a durable moat. It is also, for most organizations, 80% a people and process problem and 20% a technology problem.
The other thing worth flagging: masking policies need to follow agents across environments. A masking policy scoped to a single Snowflake account is already insufficient for the agentic architectures most enterprises are building, where agents reach across cloud boundaries, query third-party data sources, and chain actions across multiple platforms. This is a design requirement, not a future consideration.
What I’d Do Next
- Context management should be framed as a business initiative, not a data engineering project. The conversation is: how does institutional knowledge get captured, validated, versioned, and made reliably available? That is closer to knowledge management than pipeline work.
- One of the most practical suggestions from the governance session: ask CoCo for a current governance posture report before building anything else. It surfaces gaps fast and creates a baseline for a real action plan.
- Agent-level masking is a new design surface that most data teams have not worked through yet. Every data product needs a definition of what agents can surface, at what level of detail, under what conditions.
- Design for heterogeneous environments from day one. Governance that only works inside Snowflake is not governance — it is a perimeter around one part of your data estate.
Act III — The Liberation of Data
Interoperability is not a feature — it is the architectural bet enterprises need to make now.
What Stood Out
The third act was about removing the walls — between clouds, between platforms, between vendors.
- Apache Iceberg v3 + Apache Polaris — full bidirectional read/write integration announced. Snowflake is currently the only vendor delivering this. The Open Semantic Interchange Group was also launched — a cross-industry effort to standardize how semantic metadata travels between platforms.
- Open Sharing moved to public preview, enabling data sharing that extends beyond Snowflake-to-Snowflake boundaries.
- Multi-party Collaboration announced, enabling governed data exchange across organizational lines.
- Zero-Copy Integrations — direct query on non-Snowflake data without movement. SAP integration reached GA. The ability to query data where it lives, without replication, is quietly one of the most operationally significant capabilities on the platform right now.
- Snowflake Postgres GA and PG Lake GA — expanding the range of data that can be governed and queried without requiring migration.
One of the sessions I attended reinforced something I had already been thinking: the most significant barrier to enterprise AI adoption is not model capability. It is fragmented data and the fear of committing to an architecture that locks you in. The enterprises moving fastest are the ones that resolved the lock-in question early — and resolved it in favor of openness.
Why It Matters
There is a philosophical argument that Snowflake is making here, and I think it deserves to be taken seriously: the vendor that wins the agentic enterprise will be the one that makes it easiest to use any data, from anywhere, without moving it. That is a very different value proposition from the data warehouse era, and it requires a very different way of thinking about data architecture.
The Iceberg/Polaris bidirectional integration is a real technical differentiator today. But the more important signal is what it says about direction. Open table formats, open catalog standards, and universal semantic interchange are not just interoperability features — they are the infrastructure layer that makes agentic applications trustworthy at scale. An agent that can only see part of the enterprise’s data is an agent that will give you incomplete answers and erode trust quickly.
I have spent a good portion of my career helping enterprises get their data out of legacy silos and into modern platforms. The next version of that problem is not moving data between old systems and new ones — it is ensuring that data, wherever it lives, is semantically consistent, governed uniformly, and accessible to agents without requiring duplication or manual synchronization. That is the interoperability problem worth solving right now.
What I’d Do Next
- Every new data lake investment should start with Iceberg as the table format. This is no longer an advanced or experimental choice — it is the default for anything that needs to last.
- Federated governance is a design principle, not a future milestone. Classification profiles, semantic tags, and access policies need to propagate across accounts and platforms from the start, not be retrofitted later.
- Zero-copy integration patterns need to become a standard part of architecture reviews. If data is being replicated between platforms unnecessarily, that is a cost, a governance, and a freshness problem all at once.
Act IV — The Omnipresence of Intelligence
Agentic capabilities are leaving the data team — and that changes everything.

What Stood Out
The final act was the most forward-looking, and for me personally, the one that connected most directly to where I see enterprise AI going over the next two years.
The message was direct: intelligence should not require a data scientist, a BI report, or a SQL query. It should be available to every person in an organization, in the tools they already use, at the moment they need it.
CoWork — Snowflake’s personal work agent — was positioned as the knowledge worker’s interface to the agentic enterprise. It natively supports Skills (composable, reusable agent capabilities), MCP connectors, deep research across governed data, mobile access, and shareable artifacts.
Cortex Sense was announced as the runtime layer that makes this reliable without requiring constant prompt tuning — it automatically surfaces relevant business definitions, data context, and operational metadata, increasing agent accuracy by a claimed 3–4x. This is significant because one of the biggest trust barriers for enterprise agent adoption is inconsistency. An agent that gives different answers to the same question on different days destroys confidence quickly.
The Natoma acquisition brings enterprise MCP connectivity natively into Snowflake — meaning that when an agent reaches out to an external system, that interaction is still governed by Snowflake’s security controls. That matters more than it might appear on first read.
The session I found most practically useful across the entire Summit was on building enterprise agents powered by skills. The core argument was one I want to spend a moment on, because I think it is the right framing: skills, not agents, are the fundamental unit of the agentic enterprise. An agent is an orchestrator. A skill is the domain capability — governed, reusable, composable — that the agent calls on. Building your AI capability as a library of skills rather than a collection of bespoke agents changes how you think about reuse, maintenance, and governance.
The Enterprise Concierge model demonstrated in that session brought this to life in a way that I think is directly applicable for enterprises trying to figure out where to start. Rather than asking users to know which tool, which agent, or which dashboard to go to, a single conversational interface routes them to the right specialized capability. The framing used was memorable: why should users navigate to multiple places to get what they want? A sales rep running pre-call planning, logging a call summary, and requesting an expense report should not have to leave a single interface or know which underlying system handles each request.
One session featured a global enterprise in consumer electronics that built a product launch intelligence agent. During high-velocity launch windows — where the speed of data made traditional analytics too slow to act on — the agent did not just surface insights. It produced plans. It compared launch performance against prior cycles, recommended promotional adjustments, identified new customer segments, and suggested pricing actions — all in near real time. The comment that stayed with me: AI makes data faster. And data makes AI go faster. That compounding loop is what the agentic enterprise is actually about.
Why It Matters
The most significant shift from this Summit was not a product announcement — it was a redefinition of who AI is built for. When CoWork is embedded in the daily workflow of every knowledge worker, the data team stops being the bottleneck and gatekeeper of intelligence. Every sales rep, every operations manager, every finance analyst becomes an active participant in the AI value chain.
That creates both an enormous opportunity and a real risk. The opportunity is compounding returns from broad adoption — more users, more feedback loops, more signal to improve skills and context over time. The risk is that without the right architecture, agent sprawl leads to inconsistent answers, ungoverned data access, and rapid erosion of user trust.
I keep coming back to the Enterprise Concierge as the right architectural pattern for this moment. A single, governed, extensible entry point — backed by a library of curated skills and a well-maintained context layer — is how enterprises scale agent adoption without losing control. This is not speculative. The platform primitives exist today. The pattern is proven. What most organizations lack is not the technology — it is the clarity of design and the discipline to build it right the first time.
What I’d Do Next
- Start the concierge conversation with one business domain, not the whole enterprise. Pick the domain where data quality is highest, context is clearest, and business impact is most measurable. Build a governed concierge that routes to three to five curated skills. Demonstrate the model, then scale it.
- Treat skills as data products — composable, versioned, documented, and owned by a domain. An agent capability built once and buried in a single use case is technical debt. A skill built once and reused across multiple agents and workflows is a platform asset.
- The blocker for most enterprises is not the technology layer. CoCo and CoWork are available now. The blocker is the readiness of their data and context to be reliably consumed by agents. That readiness work is where the highest-leverage effort is.
- Do not underestimate the trust layer. The most technically sound agent fails if business users do not trust its answers. Consistency, explainability, and visible governance are not nice-to-have — they are the adoption lever.
Closing
I have been at a number of these summits over the years. The ones that stay with me are the ones where the platform narrative and the actual enterprise reality are in visible alignment — where the announcements reflect problems that real organizations are genuinely struggling with, not a roadmap written in isolation.
The agentic enterprise is not on a two-year horizon. The infrastructure is being built now. The governance primitives are available today. The architectural patterns — the Enterprise Concierge, the skills library, the context lifecycle, the Data Product Canvas — are proven and implementable with what exists on the platform right now.
What separates the organizations that will lead from the ones that will follow is not access to technology. It comes down to three questions, and how quickly and honestly they answer them:
Where is our context? Not our data. Our context — the business definitions, the institutional knowledge, the rules and relationships that make the data meaningful to agents and to the people who rely on their outputs.
Is our governance built for agents? Not for human analysts navigating a BI tool. For automated, high-velocity, multi-system actors that are about to become the most active consumers of enterprise data by a significant margin.
Are we enabling our people or protecting our processes? The organizations treating governance as a speed enabler will consistently outpace those treating it as a compliance gate.
The race is on. And the starting line is your data.
Ready to make your enterprise data agent-ready on Snowflake?
See how Infocepts combines Snowflake Cortex, enterprise context, and agent-level governance to move you from data questions to agents that act.
Prashant is a Data and AI enthusiast with close to 2 decades in designing and building applications and systems that power enterprise Data & Analytics Platforms. He is proficient in multiple programming languages and has co-created numerous enterprise-grade products in collaboration with major Cloud (Infra & Data) vendors.
Read Full Bio

