


I catalogued every sponsor at Snowflake Summit 2026, set the consultancies aside, and counted what the 158 product vendors are actually selling. The booth math says more about where enterprise data budgets are going than anything said on stage.
The Stage Is a Script. The Floor Is a Market.
Every Summit recap you’ll read this month – including ours – starts from the keynote stage. Fair enough; that’s where the announcements live. But I spent four days in San Francisco, and the most honest information wasn’t on the stage. It was on the expo floor.
Booth space at an event this size costs serious money, and nobody sponsors a category that isn’t generating pipeline. That makes the floor a dataset: a map of where two hundred companies independently concluded that enterprise budgets are moving. So I treated it like one – catalogued all 201 sponsors in the official catalog, researched what each actually sells, and classified them into functional lanes.
One housekeeping call before the numbers, because it changes them. Forty of the 201 booths are consulting firms and systems integrators – firms like ours – and three are hyperscalers. I’ve excluded all of them. (That one in five booths on this floor is an implementer is its own signal about where the industry’s bottleneck sits – delivery capacity, not software – but that’s a different post.) What remains: 158 product vendors across 13 lanes. No vendor names in what follows – the pattern matters more than the players.
The Census at a Glance
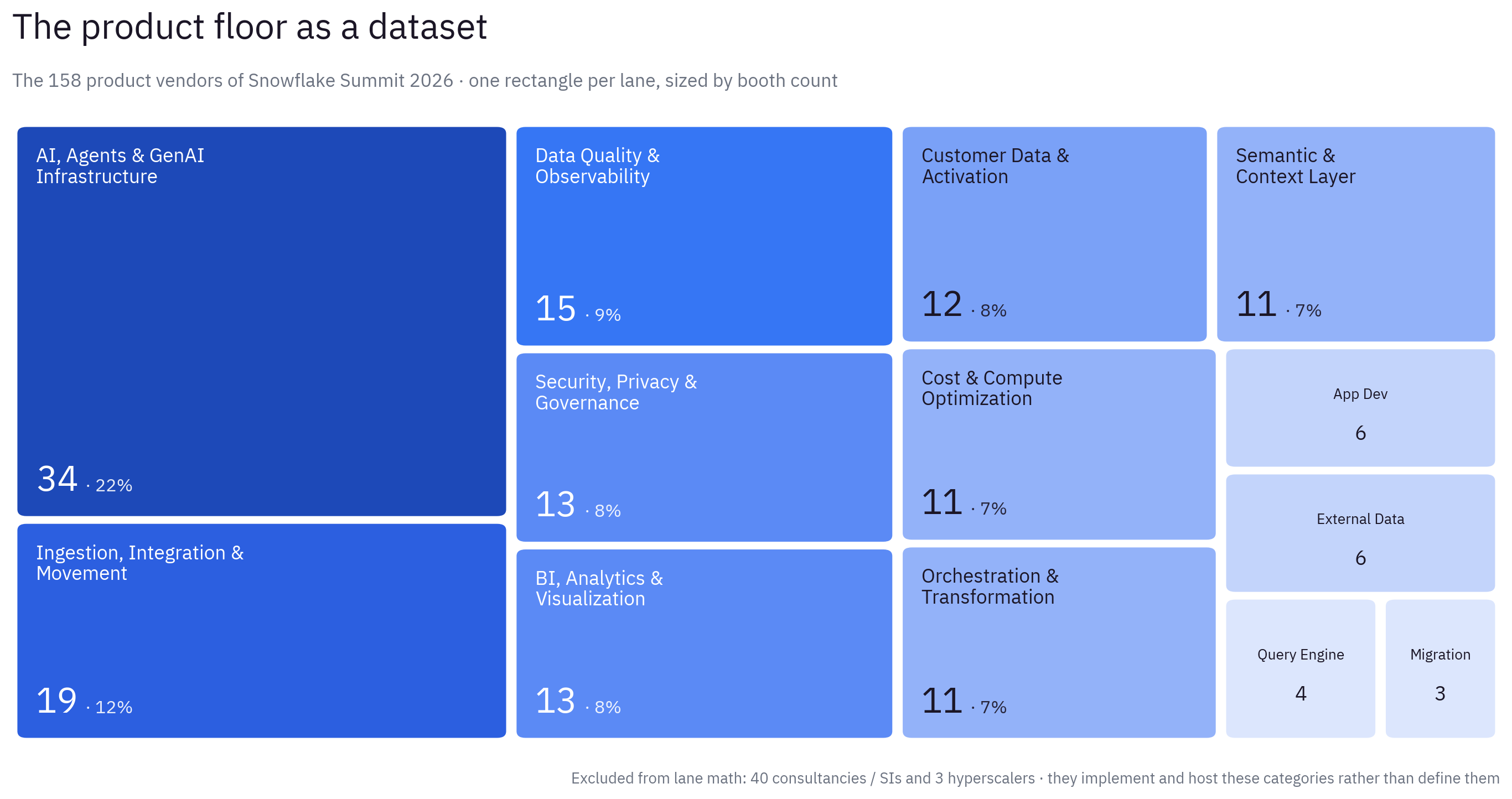
Figure 1 · The product floor: 158 vendors, 13 lanes, sized by booth count. Lanes sum to 158; classification is ours.
Three numbers set up everything that follows:
- The largest lane is AI, agents and GenAI infrastructure: 34 booths – more than one in five product vendors – and almost none of it is finished AI.
- 39 booths – one in four – sell trust (data quality, security and privacy, semantics and context) against 19 selling consumption (BI and app dev). Two to one.
- The two smallest lanes are migration (3) and query engines (4) – and that’s not because those problems went away.
For what it’s worth, the deepest crowds I saw were around the big analytics and context-layer booths. They were also the biggest booths – sponsorship tier buys square footage – so treat crowd size as a soft signal. The lane counts are the hard one.
Finding 1 – Trust Now Outdraws Consumption, Two to One
The numbers. Add the three lanes that make data and AI trustworthy – quality and observability (15), security and privacy (13), semantics and context (11) – and you get 39 booths. The lanes where humans consume data – BI (13) plus app dev (6) – total 19.
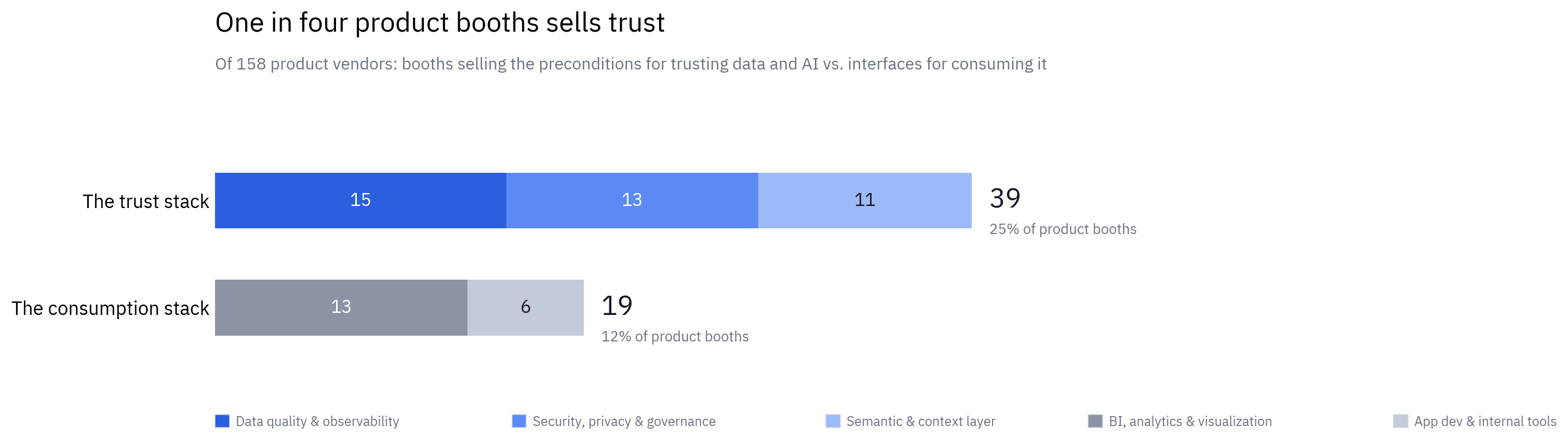
Figure 2 · Of 158 product vendors, one in four sells the preconditions for trust; one in eight sells consumption.
The reading. For a decade the consumption end was the crowded end – the dashboard was the product. That has inverted, and it’s the ecosystem pricing in the agentic shift: a dashboard consumed by a human has a built-in error handler – the human. An agent consuming the same data at machine speed has none. Everything in this cluster is really one architectural layer – a trust layer: a quality gate that data must pass, guardrails around the model, and access governance underneath. The platform said the same thing from the stage, spending keynote time on per-agent identity, guardrails and exfiltration protection – the controls that turn ungoverned automation into governed automation.
The architect’s move. Treat the trust layer as a deliverable with an owner and a budget, not a contingency line: a quality gate that agents must pass and an AI-governance design – guardrails, access control, evaluation – reviewed before the first agent ships, not after the first incident.
Finding 2 – The Biggest Lane Sells Components, Not Finished AI
The numbers. 34 booths – 21% of the product floor – sit in AI, agents and GenAI infrastructure. Look inside and very little is turnkey: vector stores, retrieval frameworks, document parsing, evaluation and testing, agent runtimes, graph stores.
The reading. Two hundred companies have collectively concluded that enterprises will assemble AI capability, not purchase it whole. That matches my delivery experience: the differentiated part of an enterprise agent is never the model – it’s the retrieval design, the embedding store, the eval harness and the gateway that brokers what each agent may touch. The model is the cheap part; the reasoning layer around it is the work.
The architect’s move. Plan AI initiatives as agentic-orchestration programs, not procurement. Define the seams – retrieval, the context layer, the eval harness, the agent gateway – and decide who owns each, because nobody on that floor owns them all.
Finding 3 – Eleven Companies Exist to Shrink One Line on Your Invoice
The numbers. Eleven booths – 7% of the product floor, as many as the entire semantic lane – are dedicated to cost and compute optimization. Their whole business is reducing what enterprises spend on the platform hosting the event.
The reading. This is the finding that physically stopped me on day one. The demo that held my attention wasn’t an agent writing SQL – it was FinOps with AI: a cost monitor that doesn’t just report spend but recommends and right-sizes, optimization as a continuous, self-healing loop rather than a quarterly cleanup. And the platform validated the lane from the main stage with adaptive compute and AI cost controls – per-user quotas, shared budgets. When the vendor and eleven of its partners monetize the same pain, believe the pain.
It’s about to compound: agents query at machine speed, around the clock, and chain their own follow-ups. Per-user quotas exist precisely because some “users” won’t be people. A retail client of mine is living this sequence right now – the optimization basics are done, and what’s needed next are concrete measures: quotas, budgets, attribution. Not more dashboards. This is one of the places we’ve planted a flag, for exactly this reason.
The obvious question is whether this lane survives the platform building the same controls natively – or becomes the next quiet lane. I think it survives, and the sharper vendors are already showing why: proactivity. The platform’s own coding agent can tune an expensive query – when you ask it to. The cost specialists’ entire pitch is that they ask first: watching the workload continuously and bringing the recommendation to you before the invoice does.
The architect’s move. Make FinOps a design input to agent architecture, not a monthly audit – budgets and quotas per agent workflow, tied to the revenue, COGS or SG&A line it serves, agreed in the design review. Run it as a platformized managed service so the loop never lapses.
Finding 4 – The Quiet Lanes Are the Loudest Signal
The numbers. Migration and modernization: 3 booths. Query engines: 4. The two smallest lanes on the product floor.

Figure 3 · Keynote-announced native capabilities, mapped to the partner lanes they pressure.
The reading. Lanes don’t go quiet because problems disappear; they go quiet because the platform absorbs them. This cycle the platform swallowed whole layers of the stack: AI-assisted migration, adaptive compute, managed Kafka-compatible streaming (the live-capture tier), a visual pipeline builder and a managed refinery, managed Postgres – each one a capability that supported its own vendor category not long ago. The uncomfortable corollary: internally built migration accelerators and ingestion frameworks are depreciating on the same schedule. The work wasn’t wrong when it was built. Maintaining custom plumbing in parallel with a platform that ships the same thing natively is a tax that compounds quarterly.
The architect’s move. Run a portfolio review of internal tooling against what’s now native, and fold the overlap into a data-platform modernization plan. Sunset or reposition the plumbing – and where pipelines stay, make them self-healing rather than hand-maintained. The surviving value of a custom accelerator is the domain intelligence on top, never the plumbing underneath.
Finding 5 – Every Lane Is Converging on the Same Word: Context
The numbers. If the floor had a word cloud, “context” would have eaten it. In my booth-by-booth research, vendors from at least four different lanes – quality, cataloging, orchestration, cost – described their product with that word. Quality vendors now sell “AI-readiness.” Metadata vendors have rebranded as context layers. And of the 13 booths I examined in depth, 11 run on competing platforms too – platform support is table stakes; the context IP is the product.

Figure 4 · Four lanes converging on the meaning tier. Quotes paraphrase booth positioning observed on site.
The reading. Of the six findings, this is the one I believe most. Category boundaries are dissolving toward the meaning tier – the knowledge layer that sits between raw data and AI. Pull it apart and it’s a semantic core (what a term means), a metric fabric (how a number is calculated), ontologies and a knowledge graph (how entities relate), and a golden record (the trusted version of each one) – the layer that decides whether an agent’s answer is right. It also creates a problem the floor won’t solve for you: buy best-of-breed in four lanes and you now own four partial context layers that disagree with each other.
I pressed one of the context-layer vendors on whether this was just cataloging rebranded. Their answer convinced me it isn’t: the context layer sits a level above the catalog. It reads through everything a company’s catalogs already hold, then fuses in the things catalogs never capture – tribal knowledge, internal rules, bylaws, policies; the organization’s guardrails – into one governed layer an agent can actually use.
Almost every substantive conversation I had outside the hall landed here too. One that stuck: an energy-sector prospect that wants to digitize field records and run reconciliation across unstructured files and images – matching what was asked for against what was actually delivered in the field, to cut anomalies and their cost. Strip away the AI vocabulary and that’s a context problem – the meaning isn’t in any table; it has to be constructed and governed before an agent can act on it. The same retail client I mentioned above has reached the same conclusion from the metrics side and is now building on a semantic layer. Watching that decision get made is what moved this finding from “interesting” to “inevitable” for me – and it’s the first place Infocepts has been focusing on primarily.
The architect’s move. Choose your context architecture deliberately and early – a semantic core and metric fabric are harder to migrate than tables, which makes this a bigger lock-in decision than the warehouse. One governed place where definitions live; every other tool consumes from it, none owns its own copy.
Finding 6 – The Newest Booths Are Building the Accuracy Stack
The numbers. Set aside the established names and the newest, smallest companies form a coherent cluster: knowledge graphs and ontology-based reasoning, formal rule-based inference alongside language models, adversarial testing and red-teaming, model evaluation, autonomous data-error detection.
The reading. Call it the accuracy-and-trust frontier – the bet that the next gains come from structure (ontologies and knowledge graphs that ground the model) and verification (an eval harness plus guardrails that catch it when it drifts), not bigger models. It’s responsible AI turned into running infrastructure. One observation keeps me from dismissing it: every agent demo I watched at Summit handled the happy path, and not one – that I saw – handled a failure live. The evaluation and red-teaming booths exist because of that gap. Still, full disclosure: of the six findings, this is the one I’d bet on last. Emerging-booth signals have a decent hit rate – the semantic layer made this exact journey from fringe idea to 11-booth lane – but decent isn’t certain, and some of these companies won’t exist in two years. I’d still take the pilot; I just wouldn’t take the prediction to the bank.
The architect’s move. Pilot one capability, scoped small: graph-grounded retrieval (an ontology behind an existing agent) or an eval harness with adversarial test cases for one already in production. Low risk, high learning.
How to Read a Floor
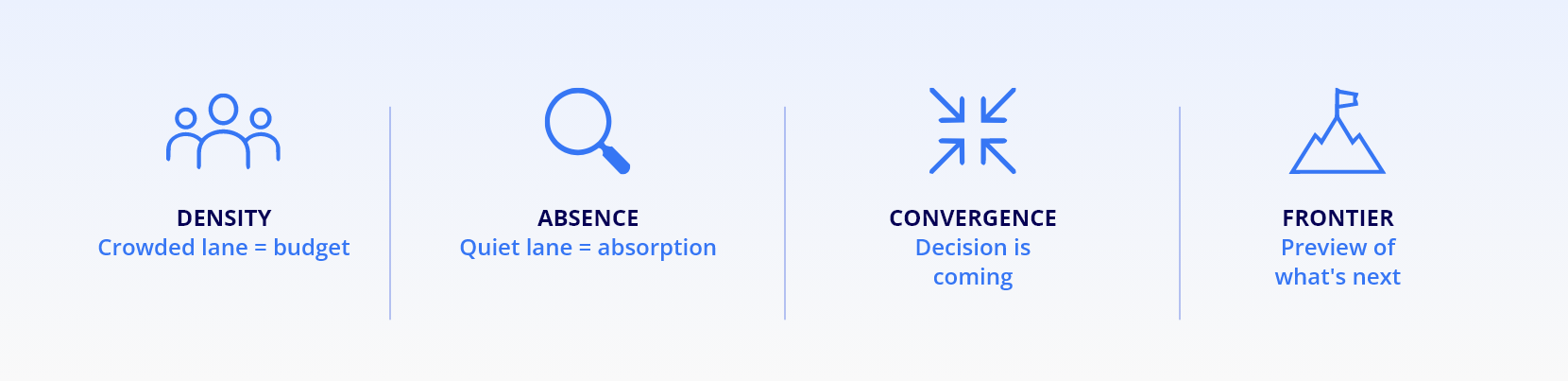
Strip the specifics and a method remains.
Density means budget – a crowded lane means many companies independently verified that enterprises are paying for that problem now.
Absence means absorption – quiet lanes usually mean the platform ate the problem; check your internal tooling before your maintenance budget does.
Convergence means a decision is coming – when four lanes sell the same word, pick your architecture before you own four versions of the truth.
The frontier is a preview – what the smallest booths agree on tends to reach the keynote within two years.
And one thing I went looking for but didn’t find: something to call overhyped. I walked that floor wanting to dunk on at least one lane and came back empty – the bets mostly match what I see in client work. The risk isn’t direction. It’s sequencing.
Three questions worth taking back:
Where does your stack sit against the crowded lanes? Quality, governance, context and cost are where the market’s conviction is – an honest self-assessment against those four finds your gaps fastest.
What are you still building that the platform now ships? Every quarter of parallel maintenance is budget not spent on what only you can build.
Where will your agents get their meaning? Pick the context architecture before you scale the agents – the floor just told you everyone will try to sell you one.
Where We’ve Planted Our Flags
Infocepts is focused on four. Semantic / Context comes first – a governed Semantic Core and Metric Fabric so a metric means one thing across BI, SQL and agents; it’s where my own client work already lives. Platformized managed services for FinOps is close behind – turning cost from a quarterly surprise into a continuously governed line. Then data quality as AI-readiness – a Quality Gate that agent deployments must clear – and AI governance with guardrails and an eval harness built in from the design review, not bolted on after an incident.
The stage told you what the platform intends; the floor told you what the market believes. They agree on the destination – the agentic enterprise – but the floor is more honest about the work in between.
Method note: Counts reflect Infocepts’ functional classification of the 201 sponsors in the official Snowflake Summit 2026 catalog, based on each company’s published positioning. 40 services/SI sponsors and 3 cloud platforms are excluded from lane analysis – implementers and hosts amplify product categories rather than define them. Companies operating in multiple lanes are counted once, in their primary lane; a small number of early-stage sponsors were classified best-effort. Platform capabilities referenced are as announced in the Summit 2026 keynotes. The portability figure (11 of 13) refers to booths researched in depth on site.
Ready to act on what the floor is telling you?
Infocepts helps enterprises build what the market just voted for - a governed semantic core, a quality gate in front of every agent, FinOps discipline by design, and the delivery depth to put it in production.
Suraj is a Data & Analytics architect with close to two decades of experience designing and building the platforms that power enterprise data, analytics, and AI. He leads global delivery teams and focuses on agent-ready data foundations — governed semantic layers, data quality, and cost-disciplined architecture for the agentic enterprise.
Read Full Bio

